
TEZ UP YOUR RODBC HIVE QUERIES
In this post I will show you how you can add TEZ options to your Hive ODBC connection and thus your RODBC queries in R.
Hive only a few years ago was rare occurrence in most corporate data warehouses, but these days Hive, Spark, Tez, among others open source data warehouses are all the buzz in the corporate world and data analysts need to adapt to this changing world.
Discovering Tez
Coming from working in a relational database environment I find developing reports and analytics in Hive rather slow. It gets even more slow when you are trying to get data out of Hive using ODBC or JDBC because the data has to travel across the network. In the case where the data is considered big data, you can build a small ( < 100mil rows ) sample of your data to work with, but you still need to run that Hive query to get the data out and there are little to no advantages of map reduce on small data.
Recently a coworker of my shared some code with me to run in HUE (web interface to Hive) which included some Tez options at the beginning of the query. I could not believe the improvements in my Hive queries once I ran this at the start of my session. Note, that you only have to run it once per session. It was especially impressive when working with smaller datasets and with queries that were pulling smaller data from tables that had lots of data. Using “limit” also produce rather quick results for my queries, which is great when you are iterating through your data build and you want to look at your data often.
Server Side Properties
This post makes the assumption that you have an ODBC connection set up for your Hive environment. If you do not, you can start by download the Hortonworks ODBC Driver for Apache Hive if you are using Hortonworks here and go to the “HFP Add-Ons” link on the left hand side menu. You will have to work with your hadoop administrator to get the configs for your connection.
Once I realized that you can add Tez options to you Hive queries, I was on the hunt to try to add it to my ODBC connection. I found it hard to believe that there was no way to do this if Tez options where available for Hive. I search for several days with no luck until I came across a small post on the Hortonworks community website here.
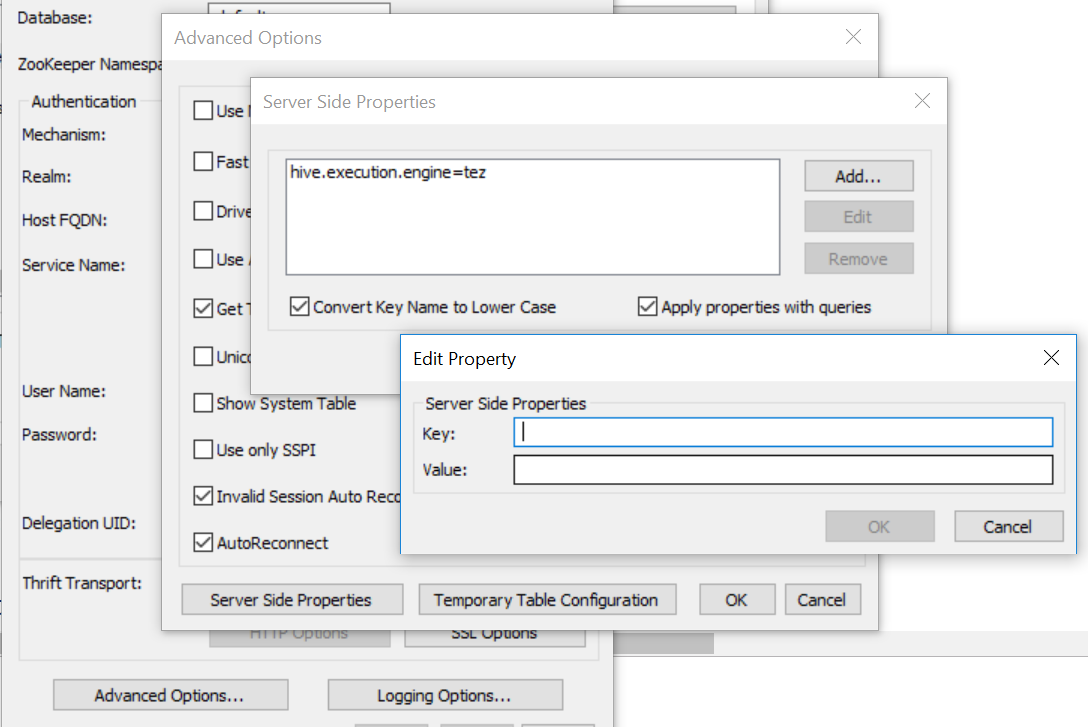
The instructions from the post are below and I have added a visual that includes all the windows layered on top of each other:
- In ODBC driver configuration, go to Advanced Options
- Click on Server Side Properties button
- Click Add button
- In Key add hive.execution.engine and Value add “tez” or “mr” (without quotes).
- Ensure to check “Apply properties with queries” - Add by me.
- Click ok and confirm the rest
Conclusion:
Your RODBC queries now will run with options each time you make a connection using con <- RODBC::dbConnect("DSN", uid = .uid, pwd = .pwd), no extra options needed in your connection string. If you run Tez options when you first log into your Hue session, you will see some pretty impressive improvements in the speed of your queries. The change has been so drastic that I have been using Hue a lot more for development lately. From my understanding, Tez will replace Map Reduce as the standard in Hive 3.0, so these options will only change what your administrator has set for the defaults.
References
Tez Config: https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
R-bloggers: https://www.r-bloggers.com/
Kudos for the Tez image goes to:
Apache software foundation - Apache Tez, Apache, the Apache feather logo, and the Apache Tez project logos are trademarks of The Apache Software Foundation. All other marks mentioned may be trademarks or registered trademarks of their respective owners.